
People have been telling me not to teach caret anymore, albeit I do teach TidyModels as well. Their argument is that TidyModels is new and shiny and we should be using the most up to date tools. I get this justification, but is caret really dead? My answer is “not by a long shot!“. Hats off to Max Kuhn and the team for rolling out these awesome packages and without Max, modelling in R would not be as easy and fun.
How they stack up?
This is not really a fair comparison, as CARET is a single ML package with hundreds of modelling algorithms, whereas TidyModels is a collection of ML based packages, including:
- rsample: for data splitting and resampling, such as K Fold cross validation
- parsnip: what I should be comparing caret with, as this is the modelling driver package
- recipes: for pre-processing
- workflow: for creating a ML workflow, similar to sci-kit learns pipeline function
- yardstick: a suite of evaluation metrics for ML models
- Baguette: a model ensembling bagging algorithm
- stacks: a suite of tools for model stacking, such as average voting algorithms
- broom: a package for tidying the outputs of models
- dials: a package for common hyperparameter tuning functions
What I like about TidyModels is that have integrated Keras and are working on building in H2O models to their pipelines.
| TidyModels | Caret |
|---|---|
| TidyModels | Caret |
| Collection of tools for ML | Many more algorithms than TidyModels: models: A List of Available Models in train in caret: Classification and Regression Training (rdrr.io) |
| Documentation limited compared to caret | Wealth of documentation and vignettes |
| Pipe orientated (more preferable to the tidy converts among us) | Feels more like base R |
| Still being developed so lots more new features for the future | Still maintained, but not actively developed |
This is not an exhaustive comparison, and as I have already admitted, we are comparing apples with pears here.
What do the trends look like for TidyModels vs CARET usage in R?
I have been recently toying with a function to retrieve the number of package downloads per month. I have written an article about this on the NHS-R Community website. This function takes in a vector of package names and will return a tibble, summary and ggplot chart.
This then spurred me on to investigate: “is caret really dying off?” and “how popular is tidymodels becoming?” I then also compare caret vs parsnip to get a more reflective comparison.
CARET vs TidyModels monthly downloads
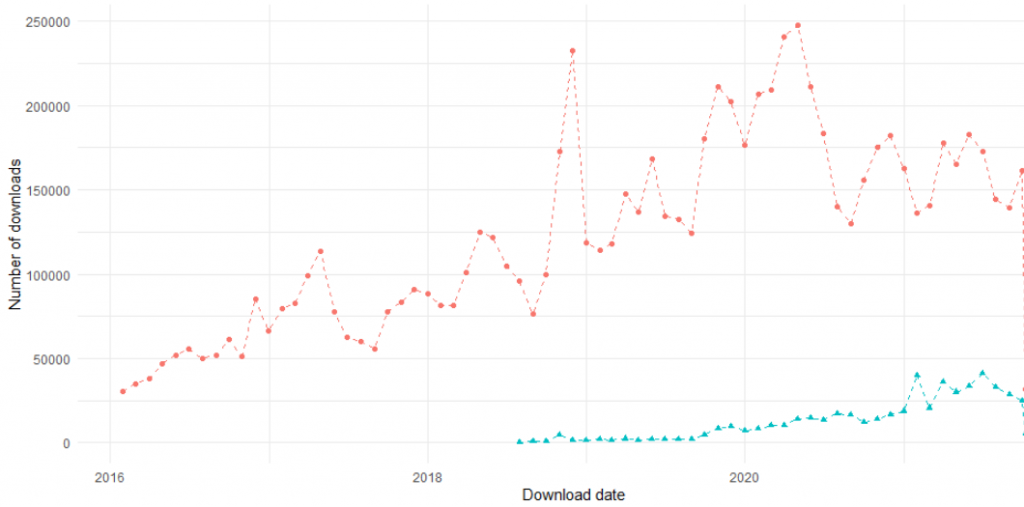
In terms of downloads, if that is our metric for popularity and usage, caret is starting to show a downward concavity from spring 2020 and tidymodels is showing a increase more or less month by month. However, the scale of magnitude between the packages is staggering.
CARET vs parsnip monthly downloads
Next, to examine how is looks against parsnip?
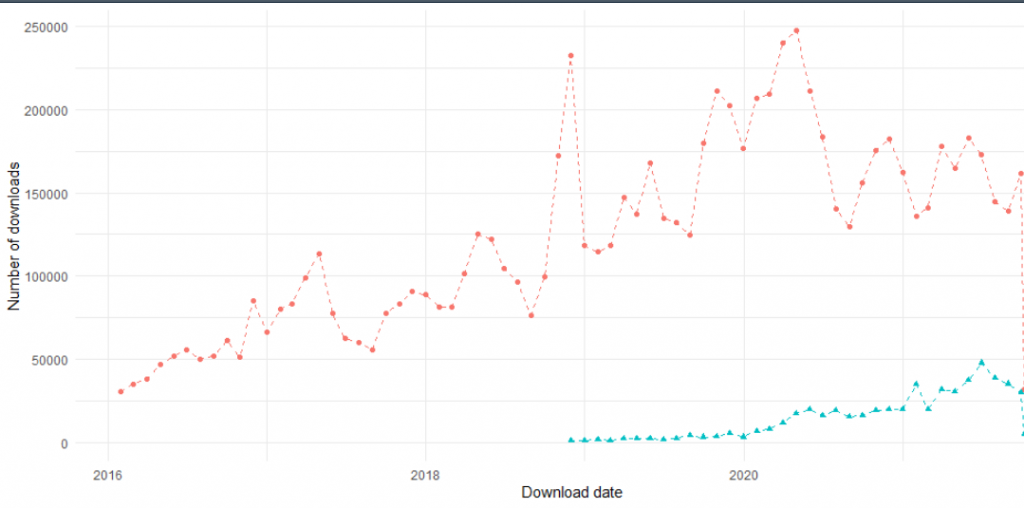
Parsnip shows a similar upward trend, until a short downturn recently. This shows that caret is still downloaded, a lot, but TidyModels is on the rise.
Where to learn?
I have made a couple of tutorials on caret, or TidyModels. These were focussed on a ML classification task and can be directly compared.
Learn CARET
Learn TidyModels
First part on data cleaning with recipes and model fitting with parsnip.
Yardstick is then used for evaluation. The second tutorial is on making your model better with resampling and hyperparameter tuning:
A shout out to the ConfusionTableR package
Included in this workshop is a reference to the ConfusionTableR package that I have created to tidy outputs of classification models. This has recently been updated, so learn how to use this package here:
Closing statements and where to get the content
I think that caret is still a really good package, but I can also see where the excitement is coming from for the TidyModels package. I personally like both for different reasons, some of which I cannot put down on paper, but to say that caret should not be taught still is incorrect, as there are lots of industries and organisation still using this excellent package.
Content wise:
- CARET tutorial – this is the caret training GitHub
- TidyModels classification model – this is the ‘build a model from scratch’ content
- ConfusionTableR – this is the content for the package for tidying confusion matrix outputs for database storage
- PackageTracker – function to track packages, as contained in this article.
If you don’t like the modelling packages in R then there is always sci-kit learn!
Thanks folks and see you again!