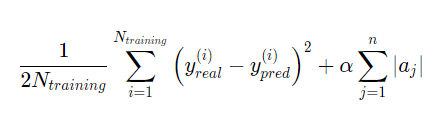The motivation for this package is simple, while there are many packages that do similar things, few of them perform automated removal of the features from your models. This was the motivation, plus having them all in one location to enable you to easily find them, otherwise you would be looking through Caret, Tidymodels and mlr3 documentation all day long.
What the package does?
The package, as of today, has two feature selection methods baked into it. These will be described in detail hereunder.
Recursive Feature Ellimination
The trick to this is to use cross-validation, or repeated cross-validation, to eliminate n features from the model. This is achieved by fitting the model multiple times at each step, removing the weakest features, determining by either the coefficients in the model, or by the feature importance attributes in the model.
Within the package there is a number of different types you can utilise:
- rfFuncs – this uses random forests method of assessing the mean decrease in accuracy over the features of interest i.e. the x (independent variables) and through the recursive nature of the algorithm looks at which IVs have the largest affect on the mean decrease in accuracy for the predicted y. The algorithm then purges the features with a low feature importance, those that have little effect on changing this accuracy metric.
- nbFuncs – this uses the naive bayes algorithm to assess those features that have the greatest affect on the overall probability of the dependent variable. Utilising the affect for the priori and the posterior. Naive is due to assuming all the variables in the model are equally as important at the outset of the test.
- treebagFuncs – explains how many times a variable occurs as decision node. The number of occurrence and the position of a given decision node in the tree give an indication of the importance of the respective predictor. The more often a variable occurs, and the closer a decision node is to the root node, the more important is the variable and the node, respectively.
- lmFuncs – sum of squared errors from the regression line, with the important variables being defined to have deviation outside of the expect gaussian distribution.
See the underlying caretFuncs() documentation.
The model implements all these methods. I will utilise the random forest variable importance selection method, as this is quick to train on our test dataset.
Removing High Correlated Features – multicol_terminatoR
The main reason you would want to do this is to avoid multicollinearity. This is an effect caused when there are high intercorrelations among two or more independent variables in linear models, this is not so much of a problem with non-linear models, such as trees, but can still cause high variance in the models, thus scaling of independent variables is always recommended.
Why bother about multicollinearity?
In general, multicollinearity can lead to wider confidence intervals that produce less reliable probabilities in terms of the effect of independent variables in a model. That is, the statistical inferences from a model with multicollinearity may not be dependable.
Key takeaways:
- Multicollinearity is a statistical concept where independent variables in a model are correlated.
- Multicollinearity among independent variables will result in less reliable statistical inferences.
- It is better to use independent variables that are not correlated or repetitive when building multiple regression models that use two or more variables.
This is why you would want to remove highly correlated features.
Learn how to use the package?
The associated vignette is the best place to learn about all the features and how to use them in the model. Also, see the supporting GitHub for help with installation and getting started.
Alternatively, I have made a YouTube video for this version to get you familiar with how the package works:
What’s next for the package?
The package is at its first version on CRAN. However, I have plans for the next set of development.
The package can be downloaded from CRAN, or via your R environment.
- Simulated Annealing – Simulated annealing is a probabilistic technique for approximating the global optimum of a given function. Specifically, it is a metaheuristic to approximate global optimization in a large search space for an optimization problem. It is often used when the search space is discrete.
- Lasso regression for feature selection – The great advantage of Lasso regression is that it performs a powerful, automatic feature selection. If two features are linearly correlated, their simultaneous presence will increase the value of the cost function, so Lasso regression will try to shrink the coefficient of the less important feature to 0, in order to select the best features. In English, shrinking the intercept to 0 means that the feature has no predictive importance on the dependent (y variable), or as I call it, “the thing you are trying to predict!”
- This can be described in the formula below: