
I have put together a complete guide to model training, docker file creation and then consuming your API in R.
This has arisen as part of a workshop the NHS-R community are doing around R in Production: show and tell, but instead of just making it local, I thought I would open up my part of the tutorial to everyone.
The process follows this generic process for ML model deployment:
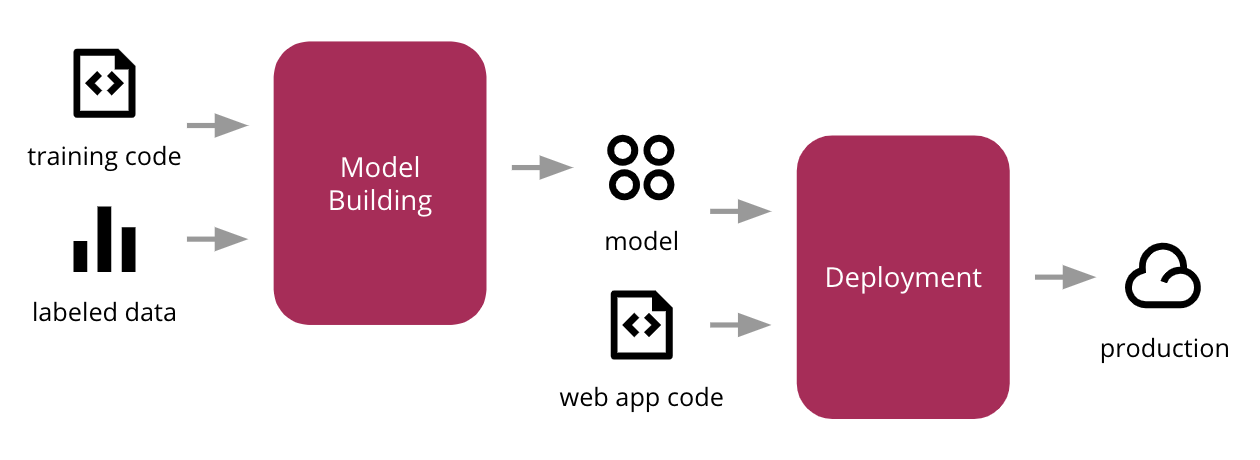
The first tutorial focuses on the training component and model building. The second tutorial focuses on Deployment via Docker and the third tutorial is the production step.
Find out how to do it all in R in the coming sections.
Training our CARET ML Classification Model
The video shows you how to train the CARET machine learning model, serialise the model and then work with PlumbeR to make our first API endpoint.
So we have this API, but it is only on my local machine. How do I productionise this? The answer is https://www.docker.com/Docker.
Please note that ConfusionTableR has changed since this tutorial, see the vignette on how to use. I attach a GitHub link where this is commented out of the supporting code.
Deploying our trained ML model to Docker
This looks at the essential elements needed to containerise your solution and push it up to Docker:
We now have our ML model in production. The question now is how do we consume it and automate the model retraining so I do not have to touch a button. The answer is in the next section.
Consuming our API with R
The final phase is to consume our API with R.
In relation to the task at hand – this is the production end of the pipeline and would be where you had live predictions from your database and you wanted to find out what the predicted class of the observation is and then use this to aid decision support, or capacity allocation decisions.
Learn how to consume the API:
Where to get the code goodies?
All the supporting code to this can be found on my GitHub repository and will be squashed and merged into the NHS-R repository as well.