
This combines my love of Deep Learning and Transformer frameworks, with the ability to generate images from textual prompts.
First of all I think I should explain a little of what is meant by stable diffusion, and this will be detailed in the next section. Then we will move on to building the stable diffusion class wrapper and we will use Streamlit to make an interactive tool to observe and generate prompts.
What is Stable Diffusion?
The diagram hereunder gives you a high level conceptual model:
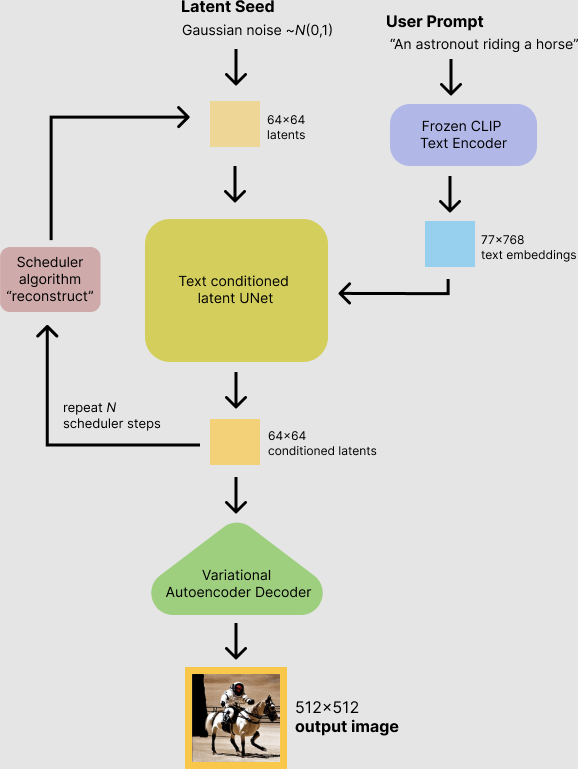
We have a text prompt i.e. an astronaut riding a horse this text is then encoded and then we pass this textual embedding to a diffusion model, which is a model that adds random noise to images, with the aim to be able to train a text / image encoder with this information. The encoder then goes through a iteration stage, adding more noise across the image patches. Finally, it is the Variational Autoencoders job is to guess which combination of text and images best represents the initial prompt. This then pumps out an output image.
This image is a very simple explanation of what is happening, the modelling underpinning this utilise a UNet (mainly used in semantic segmentation and medical imaging) and has the following functions, as described in the initial paper outlining stable diffusion:

The conditioning phase uses a semantic map to map text to representations of multiple images, these are then concatenated across the time (iterations in the loop). The images go through a diffusion model to map each pixel and generate random noise whilst going through the diffusion process. Then the unet does an up and downsampling of the Query Keys and Values in the transformer network to figure out how to filter out the noise, these are then denoised and then the predicted images are passed back out of the model in the pixel space box.
The text uses the CLIP to connect the text to images: https://openai.com/blog/clip/. The diffusion model is actually a number of models combined into a modelling framework – so far we have counted VAEs, UNets, Clip and diffusion models combined to make stable diffusion.
For a further graphical explanation of the step by step process, please refer to the excellent blog by Jay Alahammar: https://jalammar.github.io/illustrated-stable-diffusion/.
Building the Python script to sample from the diffusers packages
The next series of steps will show how to build the classes in Python to utilise an existing pretrained pipeline to produce these images. I will be doing another tutorial on how to fine tune images in a later blog post, but for now we will be using an existing pipelines as the basis for our streamlit application.
Building the Python class
The following Gist shows the Python class in its entirety. I will go through each line in a stepwise manner to allow you to understand what is going on:
Let’s start with the class constructor __init__ block. This takes in two parameters: prompt and pretrain_pipe. The prompt is the text prompt to be utilised to generate the image, as we saw at the beginning of this tutorial. The pretrained pipeline is a model backbone we will use and is from the CompVis project, with the current version of the stable diffusion model.
From there we set the self.prompt and self.pretrain_pipe variables equal to what will be input by the use of the class. We then specify that this model needs to run on a GPU device for inference, as the model can be rather resource intensive. If you don’t have a GPU then it will raise a MemoryError displaying that a GPU is needed for inference.
Finally, I use two assert statements to throw errors if the prompt and the pretrain_pipe parameters do no contain a string value.
Next, we look at the class method generate_image_from_prompt. This takes in as inputs the save_location, whether a HuggingFace token is needed and verbose to indicate if a message should be printed.
From here the following happens:
- we loaded in a StableDiffusionPipeline and use the
from_pretrainedoption to load in the pretrained pipeline we have specified in the constructor block of the class - we specify to the GPU to use a revision of floating point 16 i.e. fp16, instead of the default floating point 32 implementation with CUDA
- then I set the PyTorch data type to each
torch.float16and set theuse_auth_tokenequal to the input into the function parameter ofuse_token - I then cast the pipeline to be processed on the GPU with the
tocommand in PyTorch and then useautocastto cast the predicted / generated image to the GPU - The image is then saved into a default location and if verbose is set, an informational message will be printed
- Finally, the image is returned from the method
The last two methods you see __str__ and __len__ are dunder methods to overload the generic string and len methods of a class. Here I indicate a custom string to be printed i.e. info has been generated for the prompt [insert prompt here] entered and the len just takes the length of the prompt passed to the class.
This is all there is to it.
Building the streamlit application
You could extract the Python class at this point and save it in its own file and import into your project, but for this project I will use it at the top of my script and separate the application with an if __name__ == '__main__': wrapper. This essentially says treat everything after this part as a main.py script.
Step one – initial setup
The first couple of lines are going to set up our streamlit application:
Here we:
- Set a constant variable of
SAVE_LOCATIONto specify the name of the image that is generated and where to save it - We then use our alias (st) for Streamlit and we set the initial page config to set a title and a favicon to display in the browser tab.
- I then use a context manager (with) to load in a custom CSS stylesheet, the style sheet will change the panel background colours. The style.css can be viewed here: https://github.com/StatsGary/stable-diffusion/blob/main/streamlit_app/style.css.
- I then set a title for the main page and a caption to display underneath the title.
Step two – creating a sidebar to display image and example prompts
The next section we will create a sidebar for the web page:
st.imageloads in my HuggingFace logo from the fig folder:

- the
add_selectboxvariable uses thest.selectbox()method to add prompt examples for the diffusion model generation. I won’t list these here, but these are just some random examples I tested when developing the application - I use
st.markdownto add custom markdown at the end of the selection box - Finally, I use
st.textto display a message saying this application was developed by me
Step three – create the text prompt
The next step is to create the text_input widget to allow the prompts to be entered:
Step four – using class to generate the image from a prompt
The final ingredient in the recipe is to check that there is a prompt entered and then use our class we created earlier to pass the prompt as an input to the class to generate an image based off the prompt entered:
Here we:
- Use a spinner object to display a message on the web application to say Generating image based on prompt
- we instantiate or create a new instance of our class and create the instance name as
sdor stable diffusion, upon creating this instance we pass in the prompt (the text we need to use to generate the image) - we then use the class method
generate_image_from_promptto generate the image, which will take the prompt from the class instantiation step and then use that, but you will need to set the save location parameter i.e. the SAVE_LOCATION must match, because after the model has generated the image locally it will need to load it, and display it, on the web application - after this is happened our spinner widget gets a message to say that the generation has been successful
- The last steps are to set the image variable to open the image that has been saved locally
- Then, we use
st.imageto load the image into streamlit
There we go, we have an image generation tool to play around with until your hearts content. I will show you how this works in the next section. The full code for this implementation is saved in the streamlit_app.py file and in the GIST below:
Running the script
We will now run the script we have just created. Upon running you will see an output in the console, as below:

You will need to copy the streamlit run command and paste this in your console to run the application, upon doing this you should then be able to play with the app:

Paste the Network URL into your browser to launch the application. Once launched, you should see the application appear in your browser:

Playing with the application
Firstly I will type a prompt to generate an image, this can be seen hereunder:

In my second attempt, I will change the prompt to display homer in space:

Next I will select a prompt from the sidebar we created and let the application generate one of the images based on our default prompts:

Here we see a Van Gough-esque painting of a squirrel eating nuts. Let’s try a couple more of the default examples.

Interesing and another example:

You could have lots of fun thinking up your own examples, but I have provided a few in the tool to get you going.
Where can I get the code?
The code for this tutorial is available here:
- The supporting GitHub for this is: https://github.com/StatsGary/stable-diffusion.
- The link to the streamlit_app.py
- The link to the custom style sheet in CSS: https://github.com/StatsGary/stable-diffusion/blob/main/streamlit_app/style.css
If you use the code, please could you give the repo a star and create a pull request if you want to add any information to the repository.
Closing thoughts
I hope you have fun developing and playing around with this tutorial. I had lots of fun making it.